Mechanistic Interpretability of Semantic Abstraction in Biomedical Texts

Our NeurIPS 2025 FM4LS paper, “Mechanistic Interpretability of Semantic Abstraction in Biomedical Text”, investigates how biomedical LLMs represent technical vs. plain-language clinical texts internally, and how we can improve their ability to maintain meaning despite the style changes.
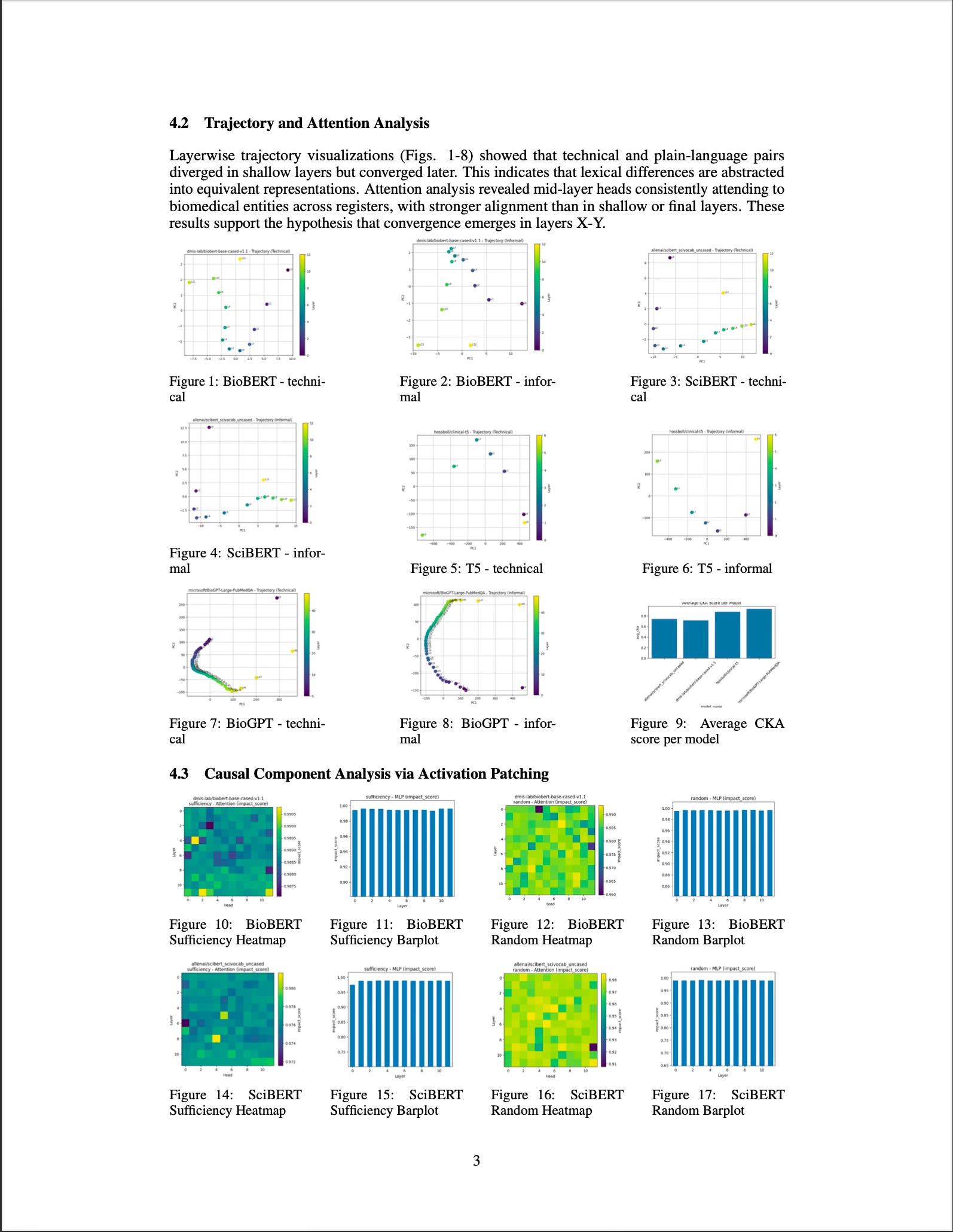
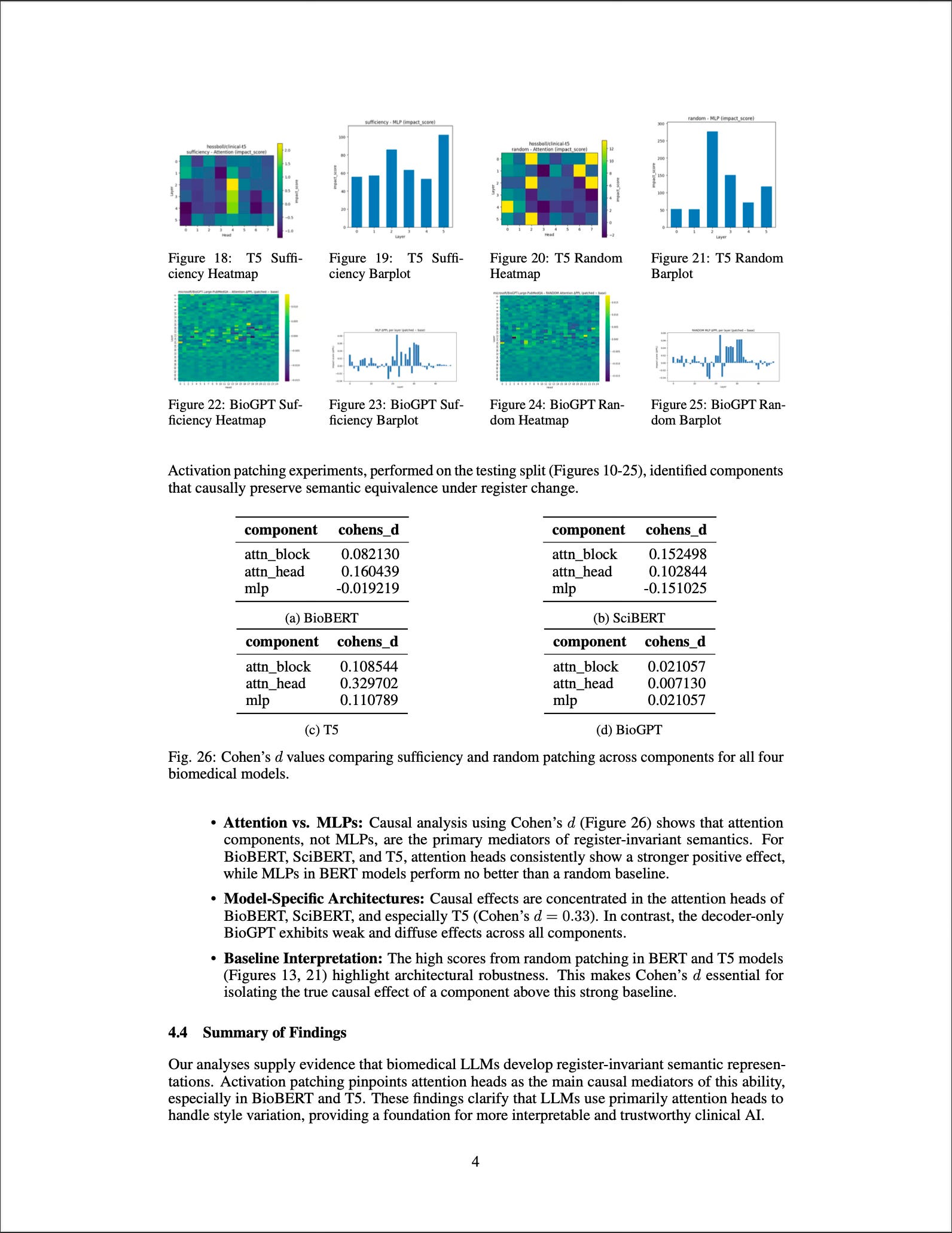
We tested models like BioBERT, Clinical-T5, SciBERT, and BioGPT on pairs of biomedical sentences that mean the same thing but differ in register. Using tools like representational similarity analysis and activation patching, we traced where and how models align meaning across registers.
Key takeaways:
Models converge to shared meaning in mid-to-late layers.
Attention heads, not MLPs, are the main drivers of semantic consistency.
Retaining key attention activations improved alignment accuracy by up to 12%.
Encoder-decoder models like Clinical-T5 handled linguistic variation most robustly.
As biomedical LLMs enter clinical contexts, interpretability becomes essential. This work takes a step toward mechanistic transparency, helping us understand why models preserve meaning and guiding the design of more trustworthy AI for healthcare communication.
Paper
OpenReview Submission (PDF Format)